
在IEEE年度Hot Chips大会上,特斯拉的FSD芯片是众多出色的演讲之一。在今年4月的自动驾驶日,特斯拉首次公开了他们的全自动驾驶(FSD)芯片。而在最近的Hot Chips 31大会上,特斯拉对芯片的一些关键组件提供了一些新的见解。

特斯拉工程师为FSD芯片和平台制定了许多主要目标。他们希望在功率范围内尽可能多地提升芯片TOPS。为了安全起见,芯片的主要设计点是在批量为一的情况下芯片的高利用率。值得注意的是,FSD芯片随附了一组用于通用处理的CPU和一个用于后处理的轻量级GPU,这不在本文的讨论范围之内。这些组件已在我们的主要文章中详细介绍。
神经处理器
尽管芯片上的大多数逻辑都使用经过行业验证的IP块来降低风险并加快开发周期,但特斯拉FSD芯片上的神经网络加速器是特斯拉硬件团队完全定制的设计。它们也是芯片上最大的组件,最重要的逻辑部分。 特斯拉谈到的一个有趣的小插曲是模拟。在开发过程中,特斯拉希望通过运行自己的内部神经网络来验证他们的NPU性能。因为他们在早期没有准备好仿真环境,所以他们求助于使用开源的Verilator模拟器,他们说这个模拟器的运行速度比商业模拟器快50倍。“我们广泛使用Verilator来证明我们的设计非常好,”特斯拉自动驾驶仪硬件高级总监Venkataramanan说。 每个FSD芯片内部有两个相同的NPU,它们物理上彼此相邻集成。当被问及使用两个NPU实例而不是一个更大的单元的原因时,特斯拉指出,每个NPU的大小都是物理设计(时序,面积,布线)的最佳选择。

ISA
NPU是具有乱序内存子系统的有序计算机。总体设计有点像是一种状态机。ISA包含最多4个带有复杂值的插槽的指令。总共只有八条指令:两条DMA读写指令、三条点积运算指令、缩放指令和元素添加指令。NPU只是简单地运行这些命令,直到点击停止命令停止它。还有一个额外的参数槽(parameters slot )可以改变指令的属性(例如,卷积运算的不同变化)。有一个标志槽(flags slot),用于处理数据依赖项(dependencies handling)。还有另一个扩展插槽,这个插槽存储了整个微程序序列的命令,这些命令在进行复杂的后处理时将被发送到SIMD单元。因此,指令从32字节到非常长的256字节不等。稍后将更详细地讨论SIMD单元。

初始操作
NPU的程序最初驻留在内存中。它们被带入NPU,并存储在命令队列中。NPU本身是一种非常出色的状态机,旨在大大减少控制开销。令队列中的命令将被解码为原始操作,并提供一组用于数据需要从何处获取的地址—这包括权重和数据。例如,如果传感器是一个新拍摄的图像传感器照片,输入缓冲区地址将指向那里。所有内容都存储在NPU内部的超大缓存中。从那以后就没有DRAM交互了。 高速缓存的容量为32 MiB,并且是高度存储的,每个bank只有一个端口。特斯拉指出,有一个复杂的bank仲裁器,连同一些编译器提示,用于减少bank冲突。每个周期中,最多可以将256个字节的数据读取到数据缓冲区中,并且最多可以将128个字节的权重读取到权重缓冲区中。根据步幅的不同,NPU可以在操作开始之前将多行数据引入数据缓冲区,以便更好地重用数据。每个NPU的组合读取带宽为384B/cycle,其本地缓存的峰值读取带宽为786 GB/s。特斯拉说,这使他们能够非常接近维持MAC正常运行所需的理论带宽峰值,通常至少80%的利用率,很多时候会达到更高的利用率。
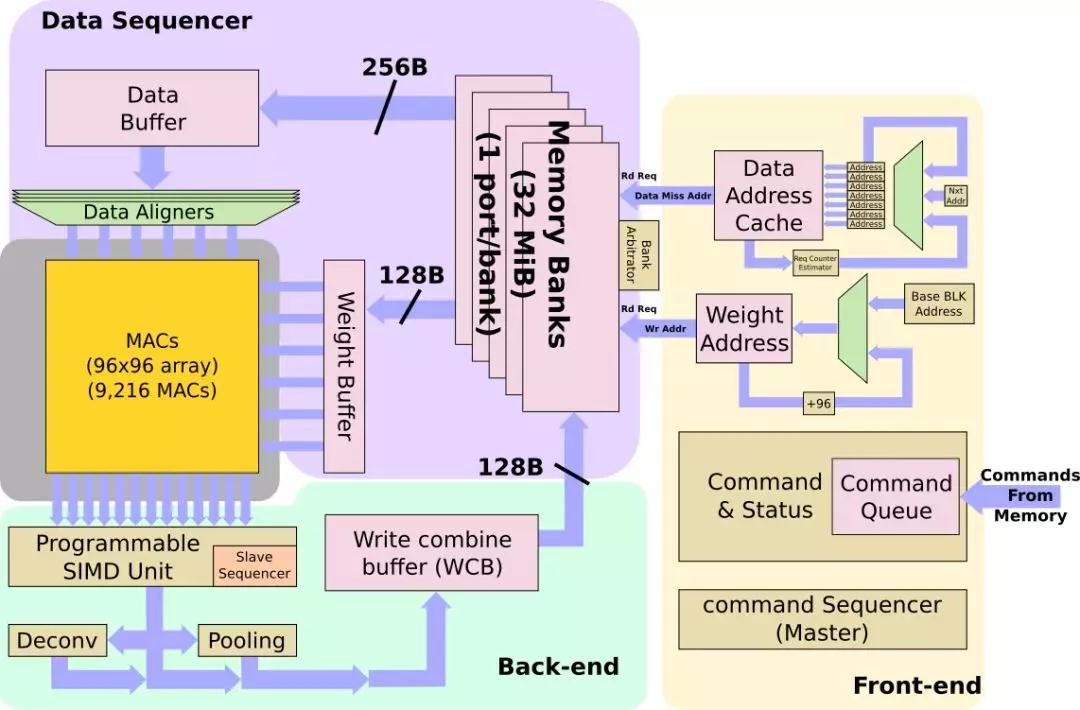
MAC阵列
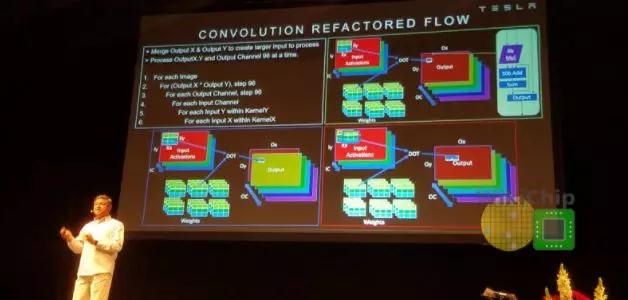
CNNs的主要操作当然是卷积,卷积占特斯拉软件在NPU上执行的所有操作的98.1%,反卷积占1.6%。在优化MAC上花费了大量的精力。 MAC阵列中的数据重用很重要,否则,即使每秒1 TB的带宽也无法满足要求。在某些设计中,为了提高性能,可以一次处理多张图像。但是,出于安全原因,延迟是其设计的关键属性,因此它们必须尽快处理单个图像。特斯拉在这里做了许多其他优化。NPU通过合并输出通道中X和Y维度上的输出像素,在多个输出通道上并行运行。这允许他们并行化工作,并同时处理96个像素。换句话说,当它们处理通道中的所有像素时,所有输入权重都是共享的。此外,它们还交换输出通道和输入通道循环(请参见下图的代码段)。这使它们能够依次处理所有输出通道,共享所有输入激活,而无需进一步的数据移动。这是带宽需求的又一个很好的降低。
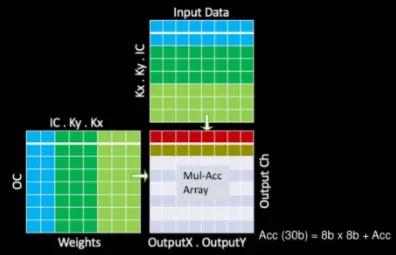
通过上述优化,可以简化MAC阵列操作。每个阵列包括9,216个MAC,并排列在96 x 96的独立单周期MAC反馈环路的单元中(请注意,这不是收缩阵列,单元间没有数据移位)。为了简化其设计并降低功耗,它们的MAC由8位乘8位整数乘法和32位整数加法组成。特斯拉自己的模型在发送给客户时都是预先量化的,因此芯片只存储8位整数中的所有数据和权重。 每个周期,输入数据的底部一行和权值的最右边一列将在整个MAC数组中公示。每个单元独立执行适当的乘法累加运算。在下一个循环中,输入数据将一行向下推,而权重网格将一行向右推。这个过程是重复的,输入数据的最底一行和权值的最右列在数组中公示。单元继续独立执行其操作。全点积卷积结束时,MAC阵列每次下移96个元素,这也是SIMD单元的吞吐量。
NPU本身实际上能够运行超过2 GHz的速度,尽管特斯拉引用了所有基于2 GHz时钟的数字,所以可以推测,这就是生产时钟。在2GHz下运行,则每个NPU的峰值计算性能为36.86 teraOPS (Int8)。NPU的总功耗为7.5 W,约占FSD功耗预算的21%。这使得它们的性能功率效率约为4.9TOPs/W,这是迄今为止我们在已出货芯片上所见过的最高效率之一,与英特尔最近宣布的NNP-I (Spring Hill)推理加速器不相上下。尽管特斯拉NPU在实际中的通用性有点可疑。但请注意,每个芯片上有两个NPU,它们消耗的总功率预算略超过40%。
SIMD单元
从MAC阵列,将一行压入SIMD单元。SIMD单元是可编程执行单元,旨在为特斯拉提供一些额外的灵活性。为此,SIMD单元为诸如sigmoid,tanh,argmax和其他各种功能提供支持。它带有自己丰富的指令集,这些指令由从机命令定序器执行。从命令排序器从前面描述的指令的扩展槽中获取操作。特斯拉表示,它支持你在普通CPU中可以找到的大多数典型指令。
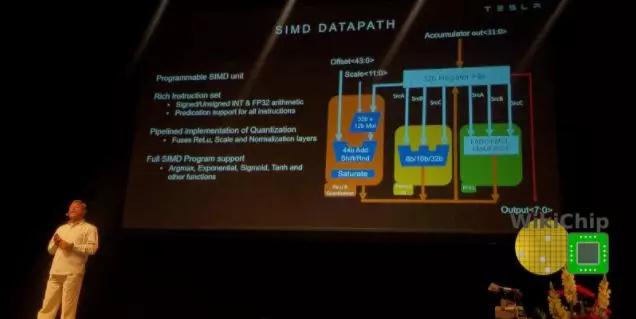
将结果从SIMD单元转发到pooling unit(如果需要),或者直接转发到write-combine,在write-combine中,结果会以128B/周期的速率被机会性地写回SRAM。该单元进行2×2和3×3的池操作,在conv单元中进行更高阶的处理。它可以进行最大池化和平均池化。对于平均池,使用基于2×2/3×3的常量的定点乘法单元替换除法。

总而言之,特斯拉实现了它的性能目标。FSD计算机(HW 3.0)的性能比上一代(HW 2.5)提高了21倍,而功耗只提高了25%。



京公网安备110402500036号
© 中国科学院微电子研究所 版权所有
地址:北京市朝阳区北土城西路3号 邮编:100029
邮箱:icac@ime.ac.cn
学习园地